物流資訊的神經網路
四層架構 × 系統家族 × 主資料治理——讓 AI 落地的三道門檻
週二早上九點,會議室裡一張訂單在三個系統顯示三種狀態:OMS 說「已出貨」、WMS 說「揀貨中」、ERP 說「待分配」——這不是罕見畫面,而是每一家規模化物流企業在導入 AI 前都會遇到的基本功課。上一篇〈物流運作的底層結構〉指出穿透五元組的資訊層才是 AI 時代的戰略核心,本文把鏡頭轉向這個資訊層——用感知、傳遞、記憶、解讀四層神經網路,串起 OMS/WMS/TMS/ERP/CRM 系統家族,並揭示 AI 落地的三道門檻。
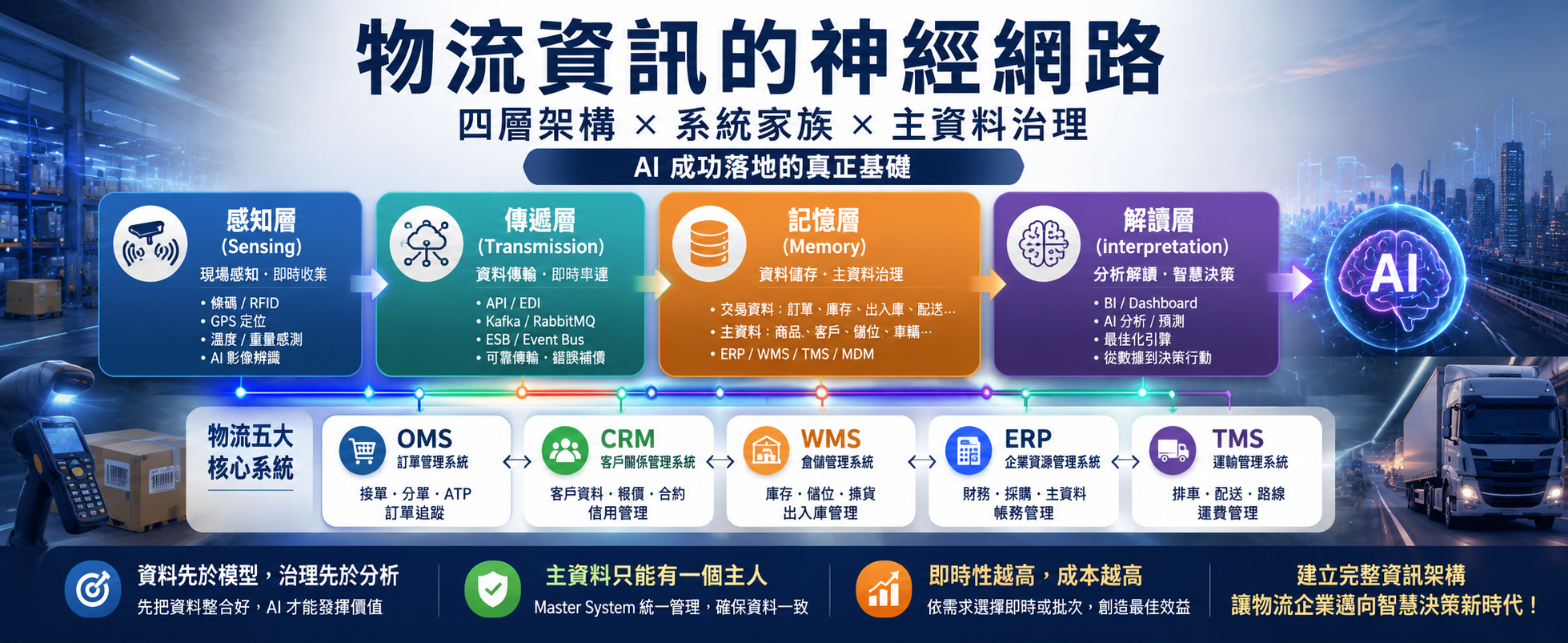
物流資訊系統不是一套系統,而是一個系統家族——OMS、WMS、TMS、ERP、CRM 各自承擔不同業務邊界與主責資料,卻必須協同對話。當家族的分工與溝通規則不清,整個物流企業的決策品質就會跟著下滑。本文提出一個便於溝通的心智模型:把物流資訊系統視為一張神經網路,由下而上分為感知、傳遞、記憶、解讀四層。每個人身體裡本來就有一套現成的範本——指尖的觸感、神經的傳導、大腦的記憶、意識的判斷,熟得不能再熟。把複雜的系統架構放進這四層,管理者、工程師、財務、業務都有地方可以「掛」自己的關切。
四層神經網路:感知、傳遞、記憶、解讀
晚上回家摸黑開門,手指碰到鑰匙孔、插入、轉動——門開了。這個動作之間發生了四件事:指尖感知金屬觸感、神經傳遞訊號到大腦、大腦從記憶調出「順時針轉」的經驗、意識解讀並發出動作指令。四個環節,缺一不可。物流公司的資訊系統本質上也是這樣一張網路——只是它要感知的是貨物、車輛、人員;傳遞的是事件、狀態、訊號;記憶的是訂單、庫存、客戶;解讀的是效率、成本、風險。
感知層是神經網路的最末梢——條碼、RFID、GPS、溫度感測器、重量秤、視覺相機。它們是資訊系統的「指尖」,負責把物理世界的事件轉為數位訊號:一件貨物經過月台,掃碼槍「嗶」一聲,是一次感知;一輛低溫車每 30 秒回報位置,也是感知。感知層的核心挑戰有三:覆蓋率(每個重要事件都被捕捉到了嗎?)、準確度(掃到的條碼、回報的座標有多精確?)、時效(從物理動作到進入系統的延遲多少?)。感知層缺陷會像神經末梢麻痺,讓整個網路失去對現場的感覺——後面再聰明的 AI 都是瞎子摸象。
傳遞層是神經網路的「軸突」,把訊號從一個神經元送到另一個。技術家族包括 EDI、API、訊息佇列、企業服務匯流排(ESB)、事件匯流排。傳遞層要回答介面設計的四個經典問題:誰通知誰?何時通知?通知格式是什麼?通知失敗怎麼辦?這四個問題沒有標準答案——即時性要求高的用同步 API,訊息量大但不需即時的用非同步訊息佇列,跨組織批次對帳用 EDI 或批次檔案。傳遞層若不穩定,整個神經網路會像中風的人——各神經元都還活著,但彼此失聯。
記憶層是神經網路的「海馬迴」——ERP、WMS、TMS 資料庫,以及主資料管理(MDM)系統。它負責兩件事:交易資料(每一張訂單、每一次入庫、每一次出車的事實紀錄)與主資料(商品、客戶、儲位、車輛的基礎檔案)。記憶層的品質決定資訊系統能不能「記得對」。同一件商品,在 OMS 叫「iPhone 15 Pro 256GB 黑色」,在 WMS 叫「IP15P-256-BLK」,在 ERP 叫「A001234-B」——如果沒有主資料管理把三個 ID 對齊,記憶層就會變成三個互不溝通的大腦。
解讀層是神經網路的「大腦皮質」——BI 儀表板、報表系統、AI 預測模型、最佳化引擎。如果前三層做對了,解讀層就能回答四類問題:發生了什麼?為什麼發生?接下來會發生什麼?應該怎麼做?但它有個前提:沒有感知、沒有傳遞、沒有記憶,再強的大腦皮質也無事可做。許多公司誤以為買一套 AI 工具就能變聰明,結果連乾淨的資料都拿不出來,AI 只能學到互相打架的垃圾,最終淪為展示用玩具。
系統家族:五個系統、四條主動脈
把鏡頭拉近到傳遞層與記憶層交界處的那一群系統——物流公司的營運系統家族。由五個主要成員組成,依服務對象由近到遠分成四個層級。
L1 分析層:BI/DW & DM是家族的仲裁者。不直接參與交易,而是從下面所有系統抽取資料、進行整合、提供分析,角色像法院:不生產,但仲裁——它必須同時接收五個營運系統的資料,才能回答「訂單履約率是多少」「哪些客戶貢獻毛利最高」這類跨系統問題。BI 解讀架構由 DW(Data Warehouse,資料倉儲)提供乾淨整合的歷史資料,再由 DM(Data Mining,資料探勘)從中萃取規則、關聯與預測模型——兩種技術合在一起,才支撐起完整的描述/診斷/預測/處方分析能力。
L2 顧客層:OMS 與 CRM面對外部世界。OMS 主責「訂單」,掌管從收單、驗證、分單、承諾(ATP)、狀態追蹤到結案的完整生命週期,介面輸入來自電商平台與客戶系統,輸出分派到 WMS(揀貨)、TMS(排車)、ERP(扣帳與應收)。CRM 主責「客戶」——聯絡資訊、歷史交易、服務互動、信用額度;在 B2B 物流裡,CRM 還負責報價、合約與費率表的維護。
L3 營運層:WMS、ERP、TMS是家族的三大支柱。這一層最「吃重」,掌管公司最核心的三種資源:貨(WMS)、錢(ERP)、車(TMS)。WMS 主責庫存與儲位,回答「什麼東西?放在哪裡?還剩多少?」;ERP 是全公司帳本中心,每一筆入庫、每一張發票最終都要留下財務足跡,通常還承擔主資料總庫的角色;TMS 主責運單與車輛,回答「這批貨由哪輛車、走什麼路線、什麼時候到?」。
L4 執行層貼近物理現場。比營運層更貼近現場——WES 指揮自動化倉儲設備(輸送帶、AGV)、MES 負責流通加工、FMS 監控車輛油耗與駕駛行為、ePOD 收集最後一哩的簽收照片與時戳。這一層特色是「資料粒度細、頻率高」,每秒都在產生訊號交給上層聚合。
四條雙向主動脈:為什麼必須是雙向
系統之間不是只有由上而下的指令流,更多是雙向協作。家族最關鍵的四條雙向連線:WMS↔OMS(可用量/預留)、OMS↔ERP(ATP/扣帳)、ERP↔CRM(信用/應收)、TMS↔CRM(到貨更新)。這四條為什麼必須是雙向?因為業務邏輯不是「上級交辦」而是「對話協商」——OMS 要問、WMS 要答;OMS 要扣、ERP 要回。任何一條設計成單向,都會讓家族變成獨裁而非協作,資料也會逐步失真。
家族界線:資料共用,主責唯一
OMS 有訂單、ERP 也有訂單、CRM 也記得客戶買過什麼,這三套系統會不會重複?答案是:資料可以共用,但主責只能一個。OMS 主責訂單的「履約狀態」,ERP 主責訂單的「財務結清」,CRM 主責訂單背後的「客戶關係」。三者看的是同一張訂單,但關注點不同——就像醫生、會計、家人面對同一位病人的角度也不同,但沒有人會質疑這三者的分工。理解這個分工,下一個問題就浮現:既然資料共用,誰來決定「商品的正確名稱是什麼」「客戶的信用額度是多少」?這就是主資料管理的戰場。
主資料治理與介面取捨:越即時越貴
物流資訊系統裡最不起眼、卻最容易爆雷的議題,是主資料管理(MDM)。不起眼是因為它不像 WMS、TMS 有炫目的功能畫面,只是一堆「基礎檔案」;容易爆雷是因為一旦主資料沒對齊,上面所有系統的數字都會對不上。
主資料 vs 交易資料:球員名冊與逐球紀錄
物流公司資料分兩大類:交易資料記錄「發生了什麼事」(訂單、入庫、運送),量大、生命週期短、持續累積;主資料記錄「參與交易的對象是誰」(商品、客戶、儲位、車輛),量相對小、生命週期長、會被多個系統共用。打個比方——交易資料是一場棒球比賽的逐球紀錄,主資料是球員名冊、球場規格、裁判名單。物流四大主檔是商品、客戶、儲位、車輛,品質直接決定作業日常運行,也最常成為資訊系統整合的戰場。
Master 與 Subscriber:每筆主資料只能有一個主責系統
處理主資料的第一原則是:每筆主資料只能有一個 Master System,其他系統都是 Subscriber。誰當 Master?原則是「業務邏輯的源頭」——商品主檔由 ERP 或 PIM 主責;客戶主檔由 CRM 或 ERP 主責;儲位主檔由 WMS 主責;車輛主檔由 TMS 或 FMS 主責。Subscriber 不可擅自修改主檔,只能透過 Master 更新、再同步下來——防止「多頭馬車」。實務上 MDM 有四種架構模式:
- Registry——僅登錄 ID 對照。
- Consolidation——複製一份到中央供報表。
- Coexistence——中央有黃金版本、各系統保留副本同步。
- Centralized——只有中央一份,所有系統直接讀寫。
沒有最好,只有最適合——許多企業的 MDM 旅程是 Registry → Consolidation → Coexistence 一步步演進。
介面的即時性光譜:越即時越貴
主資料對齊的前提是系統之間能正確對話。介面就是對話方式:同步 API 像打電話(A 撥出、等 B 回應),優點即時一致,缺點強耦合;非同步訊息佇列(Kafka、RabbitMQ)像寫信(A 丟進郵筒、B 有空再收),優點解耦彈性,缺點最終一致而非即時一致;批次檔案最古老(定時傳 CSV 或 EDI),優點穩定可靠、成本低,缺點時延高;事件驅動是非同步的進階應用,即時性與解耦兼得,但實作門檻最高。把這四種放在同一把尺上,就是即時性光譜——從月批次、日批次、小時批次,一路到分鐘級、秒級、毫秒級,越往右延遲越低,但架構成本越高:不只伺服器與頻寬,還包括維運人力、故障排查難度、跨部門協調成本。
AI 落地:從描述到處方的四階階梯
前面三節看似各自獨立——神經網路四層(§1)、系統家族分工(§2)、主資料與介面(§3)——其實鋪的都是同一條底:讓公司的資料能夠乾淨、完整、可信地抵達分析層。有了這條底,AI/BI 才有舞台可跳。這也是上一篇所提出的「資訊層三核心價值」(脈絡、可追蹤、可解釋)在資訊系統落地的具體形式。
四階分析階梯
BI 與 AI 的分析能力可分為四階,由下而上:
- Descriptive(描述性)回答「發生了什麼?」——典型工具是 BI 儀表板、報表、OLAP。
- Diagnostic(診斷性)回答「為什麼發生?」——典型工具是 BI 鑽取、根因分析、異常偵測。
- Predictive(預測性)回答「接下來會發生什麼?」——機器學習模型用歷史資料訓練,預測未來需求、到貨延遲機率、設備故障風險。
- Prescriptive(處方性)回答「應該怎麼做?」——最佳化引擎、模擬模型、決策建議系統,告訴你「最好的行動方案是 A 或 B,每個選項的代價各是多少」。
這四階不是獨立的選擇題,而是逐層向上疊加——沒有穩定的描述性報表,就做不好診斷性鑽取;沒有準確的診斷,就訓練不出可靠的預測模型;沒有預測作為基礎,處方性建議只是賭博。跳階而上,模型一定會反噬。
AI 落地的三道門檻
很多公司買了 AI 工具卻用不起來,最常見的三道門檻恰好對應前面三節的主題:
- 第一道,感知的廣度與準度(對應 §1 感知層)——AI 吃的是資料,沒有完整、準確的感知訊號,模型等於瞎子摸象。
- 第二道,主資料的治理(對應 §3 上半)——商品、客戶、儲位、車輛的主資料如果各系統打架,AI 學到的是「同一件商品的三種樣子」,模型再強也無用。
- 第三道,介面的穩定性(對應 §3 下半)——資料進入分析層的延遲高、丟包多、格式不一,BI 儀表板會抖、AI 訓練集會髒,分析結果沒人敢信。
很多公司以為 AI 是終點,其實 AI 是起點——起點的前提是資料基礎建設。資料先於模型,治理先於分析。這條順序弄反,後面投資再多都是打水漂。這正是為什麼本系列從「本體結構」(Ch1)談到「資訊神經網路」(本篇),還未進入「決策觀點」(Ch3)——因為決策建立在資料上,資料建立在資訊架構上,資訊架構建立在本體結構上。跳過任何一層,後面的 AI 都是空中閣樓。